
From Model Performance to Architectural Imperative: A New Era in Voice AI
The rapid evolution of voice AI has reached a critical inflection point. For years, the primary benchmark for success was model quality—how accurately an AI could transcribe, how intelligently it could reason, and how naturally it could speak. But as these systems transition from experimental novelties to core components of customer interaction in highly regulated sectors like finance and healthcare, the calculus has fundamentally changed. The new imperative is no longer just performance; it is governance. For modern enterprises, the foundational architecture of their voice AI stack has superseded the raw intelligence of the model as the single most important determinant of compliance, risk management, and regulatory defensibility. This article deconstructs this pivotal shift, exploring why the structural choices an organization makes today will define its ability to operate securely and responsibly in the age of conversational AI.
This fundamental reevaluation is driven by a stark reality: as the intelligence of AI models becomes a commoditized utility, the true competitive and regulatory advantage lies not in the model itself, but in the framework that deploys it. The questions have shifted from “How smart is the AI?” to “Can we prove how the AI made its decision?” and “Can we intervene in real-time to protect sensitive data?” Answering these questions has nothing to do with the elegance of a model’s output and everything to do with the transparency of its underlying architecture. As a result, business leaders are discovering that their choice of a voice AI vendor is less about procuring a smarter algorithm and more about adopting a defensible governance posture.
The Evolution from Novelty to Non-Negotiable Business Tool
Not long ago, enterprise voice AI was largely confined to rudimentary Interactive Voice Response (IVR) systems, where the main challenges were basic command recognition and routing. The stakes were relatively low, and the technology was a peripheral convenience. However, the advent of powerful Large Language Models (LLMs) has catapulted voice agents to the front lines of business operations. They now handle sensitive financial transactions, manage confidential patient data, and serve as the primary interface for complex customer support.
This transition from a simple utility to a mission-critical, data-rich system has placed voice AI squarely in the crosshairs of regulators and compliance officers. The sheer volume of Personally Identifiable Information (PII), payment details, and protected health information flowing through these conversational interfaces brings them under the purview of strict regulations like PCI-DSS, HIPAA, and GDPR. The historical focus on mere accuracy is now insufficient; the system’s entire lifecycle—from data ingress to final response—must be transparent, auditable, and controllable. This new reality demands a deeper look beyond the model’s capabilities and into the very framework that supports it.
The Architectural Crossroads: Speed, Control, and the Modern Enterprise
The contemporary market presents enterprises with three distinct architectural paths, each with profound implications for speed, user experience, and—most critically—governance. The decision between them is no longer a simple technical trade-off but a strategic choice that reflects an organization’s risk appetite and compliance posture. Understanding these pathways is essential for any leader tasked with deploying voice AI in a responsible and scalable manner.
Native S2S Architecture: The Allure of Speed vs. the Peril of Opacity
Native Speech-to-Speech (S2S) architectures, championed by major tech players, are engineered for one primary goal: minimizing latency. By processing audio inputs directly for understanding and generating a spoken response, these systems can achieve response times under 300 milliseconds, falling within the threshold for natural human conversation. This creates a remarkably fluid and engaging user experience, preserving subtle paralinguistic cues like tone and hesitation that make interactions feel more human. The appeal of this seamless performance is undeniable, promising higher customer satisfaction and engagement.
However, this speed comes at a steep price: opacity. The intermediate reasoning steps within these models operate as a “black box,” making it exceptionally difficult, if not impossible, for an enterprise to audit the decision-making process, redact sensitive Personally Identifiable Information (PII) in real-time, or enforce specific business rules. For any organization handling regulated data, this lack of transparency introduces an unacceptable level of compliance risk. It becomes impossible to prove to an auditor that specific data was handled correctly or that a particular policy was enforced during a conversation, creating a significant and often untenable liability.
The Legacy Modular Stack: Sacrificing Fluidity for Forensic Control
The traditional modular, or “chained,” architecture represents the opposite end of the spectrum. This approach breaks the process into discrete, sequential steps: a Speech-to-Text (STT) engine transcribes audio, an LLM processes the text, and a Text-to-Speech (TTS) engine synthesizes the final audio. Each component often comes from a different vendor, connected via network calls over the public internet. The primary benefit is absolute control and transparency. Each handoff between components creates an auditable, text-based surface where an enterprise can insert logic, scrub data, or inject context. This forensic-level control is ideal from a compliance standpoint.
The historical flaw, however, has been crippling latency. Each network hop between separate services adds precious milliseconds, often pushing total response time well over 500ms and resulting in the stilted, awkward interactions that frustrate users and lead to conversational breakdowns. This noticeable lag frequently causes users to interrupt the agent, assuming they were not heard, a phenomenon known as “barge-in.” While offering perfect control, the poor user experience of legacy modular systems has historically limited their viability for real-time, engaging customer interactions.
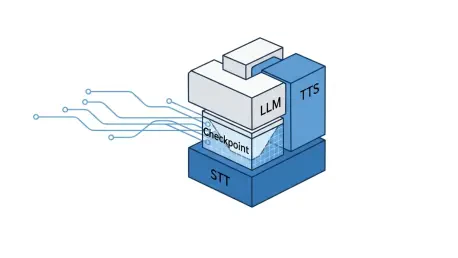
Unified Modular Architecture: The Synthesis of Speed and Governance
A new paradigm, the Unified Modular architecture, has emerged to resolve this long-standing dilemma. Innovators in this space physically co-locate the STT, LLM, and TTS models on the same GPU clusters, allowing data to be transferred via high-speed memory interconnects rather than the public internet. This clever engineering collapses the roundtrip latency to near-native levels (sub-500ms) while crucially preserving the distinct, auditable text layers of a modular system. This approach directly challenges the assumption that enterprises must sacrifice governance for speed.
This “best of both worlds” approach provides the speed necessary for a natural user experience while delivering the non-negotiable control points essential for operating in regulated environments. The text layer between transcription and speech synthesis remains fully accessible, enabling critical functions like real-time PII redaction to prevent sensitive data from ever reaching the reasoning model. It also allows for dynamic context injection (Retrieval-Augmented Generation) and deterministic control over pronunciation, ensuring a drug name or financial product is always spoken correctly. It transforms complexity from a liability into a necessary feature for robust governance.
The Commoditization of Intelligence and the Rise of the Orchestration Layer
Two powerful, concurrent trends are reshaping the future of the voice AI market. First, core AI intelligence is becoming a commodity. Tech giants are aggressively driving down the cost of powerful models, positioning raw reasoning capability as a utility rather than a differentiator. With pricing that makes voice automation economically viable for a wide range of transactional workflows, the core LLM is becoming an interchangeable component. This forces enterprises to look elsewhere for competitive advantage and sustainable value.
In response, a second trend is accelerating: the rise of the sophisticated orchestration layer. These platforms focus not on building the underlying models but on providing the critical architectural framework to manage them securely and compliantly. As models become commoditized, the value migrates upward in the technology stack to the systems that offer control, security, and auditability. The future value will lie less in the AI model itself and more in the governance infrastructure that allows an enterprise to deploy any model safely, enforce policies consistently, and maintain a complete audit trail across every interaction.
A Strategic Blueprint for Selecting Your Voice AI Architecture
For business leaders, the path forward requires a shift in evaluation criteria. Instead of beginning with a “bake-off” to find the most eloquent AI, the process must start with a thorough assessment of risk and regulatory requirements. This compliance-first approach provides a clear framework for architectural selection, ensuring that the chosen solution is not only effective but also defensible. The initial question should not be “Which model sounds best?” but “Which architecture provides the controls we need?”
This risk-based analysis leads to a clear decision-making matrix. For high-volume, low-risk transactional workflows where cost and speed are paramount, and sensitive data is not exchanged, a Native S2S architecture can be a viable and efficient solution. These use cases, such as simple appointment reminders or order status updates, benefit from the low latency and cost-effectiveness of these platforms.
However, for any interaction involving sensitive data or complex, regulated processes—the very use cases that deliver the most business value—the Unified Modular architecture becomes the de facto standard. Its ability to balance near-native performance with granular control makes it the only choice for mitigating compliance risk without sacrificing user experience. Enterprises must demand transparency from vendors, asking not just what their model can do, but how its architecture enables critical governance functions like real-time data redaction, auditable reasoning, and deterministic policy enforcement.
Conclusion: Architecture is the New Bedrock of Trust in Voice AI
As voice AI became deeply embedded in the fabric of enterprise operations, its potential for both value creation and risk exposure grew exponentially. While the fluency and intelligence of AI models continued to capture public imagination, the silent, underlying architecture was what earned the trust of customers and regulators. The ability to prove how a decision was made became just as important as the quality of the decision itself.
Ultimately, the future of enterprise voice AI was not defined by the most human-sounding agent, but by the most transparent, controllable, and fundamentally compliant architecture. For businesses navigating this new frontier, architecture was no longer a technical detail—it became the very foundation of trust, securing their license to operate and innovate responsibly in the conversational age.







